Esta entrada se publicó originalmente en Harbour Magazine, mi publicación sobre el lenguaje de programación Harbour.
He publicado en Github el codigo fuente de algunos de los programas disponibles en mi sitio web https://alanit.com. Estos programas están hechos con Harbour y FiveWinHarbour y creo que constituyen un buen punto de partida para cualquier programador que quiera iniciarse o profundizar en el conocimiento de estos lenguajes.
Esta entrada se publicó originalmente en Harbour Magazine, mi publicación sobre el lenguaje de programación Harbour.
Publicamos los videos de las ponencias de la 2ª Conferencia de programadores de Harbour Magazine. Todos los videos están en español, pero algunas de las conferencias no pudieron grabarse por problemas técnicos.
Pruebas unitarias con Harbour por Manuel Calero Solís
Esta entrada se publicó originalmente en Harbour Magazine, mi publicación sobre el lenguaje de programación Harbour.
A partir de ahora voy a intentar hacer un post mensual con las novedades relacionadas con Harbour y con otros enlaces de interés que pueden ayudar a hacerte crecer como programador Harbour. Comenzamos.
Manuel Calero Solís ha publicado las clases de hbunit que utilizó para su charla de Pruebas Unitarias con Harbour en la 2ª Reunión de programadores de Harbour Magazine. Lo tienes en https://github.com/manuelcalerosolis/hbunit
Como anunciaba en otra entrada de Harbour Magazine, uno de los temas estrella de la reunión de Calpe fue el tema de los ORM. En http://zetcode.com/python/peewee/ tienes información de PeeWee, un sencillo ORM para Python.
Cristóbal Navarro ha anunciado la próxima inclusión en FivEdit de la clase TGithub, lo que permitirá a su editor acceder al API de GitHub desde el propio FivEdit. Tienes en anuncio en http://forums.fivetechsupport.com/viewtopic.php?f=6&t=37047
¿ Tienes algún enlace que quieras compartir con al comunidad Harbour ? Envíamelo y lo publicaré en la siguiente edición de los enlaces de Harbour Magazine.
Esta entrada se publicó originalmente en Harbour Magazine, mi publicación sobre el lenguaje de programación Harbour.
Cuando hacemos una de las reuniones de Harbour Magazine, parece que lo más importante son las charlas que realizamos sobre diversos temas. No es cierto. Lo más importante son las charlas entre los asistentes, donde cada uno expone de manera informal sus experiencias e inquietudes acerca de Harbour.
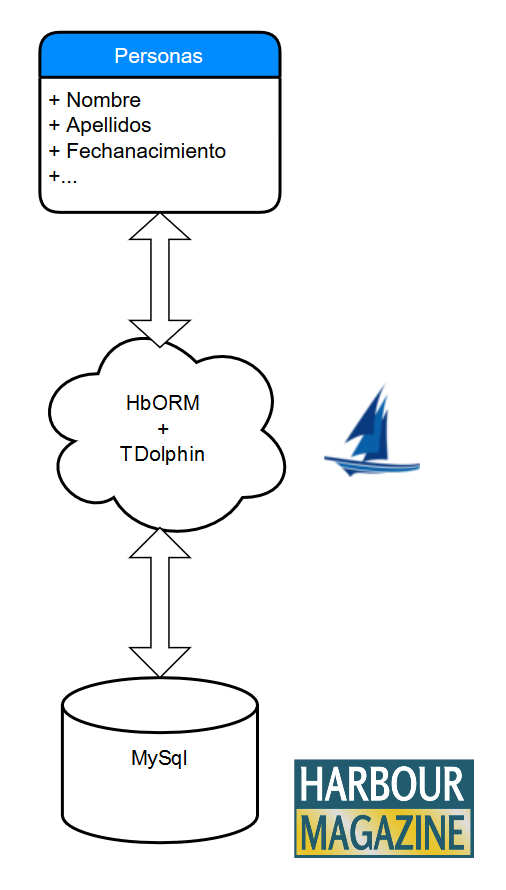
Una de estas inquietudes es la falta de un ORM para Harbour, y en la reunión de Calpe hubo bastante debate sobre el tema. Carlos Mora y Manuel Calero fueron los que más insistieron con el tema, puesto que han trabajado con ORM en otros entornos, explicando las ventajas de contar con una herramienta de este tipo para Harbour.
Fruto de estas conversaciones y algunas posteriores en un grupo de mensajería de Harbour Magazine, Antonio Linares se ha lanzado a elaborar un ORM para Harbour. Este ORM funcionará con FWH-MySql/MariaDB, FWH-ADO y también con TDolphin. La versión del ORM para TDolphin es gratuita y se puede descargar un primer prototipo desde el siguiente enlace: https://github.com/FiveTechSoft/ORM-for-Dolphin.
La 2ª Reunión de Harbour Magazine fue un éxito total. Acudieron nuevos compañeros que no pudieron venir a la 1ª Reunión y también echamos de menos a otros compañeros que no pudieron acudir.
El ambiente fue extraordinario, tanto que hubo quien adelantó una semana su llegada para poder estar más tiempo en Calpe.
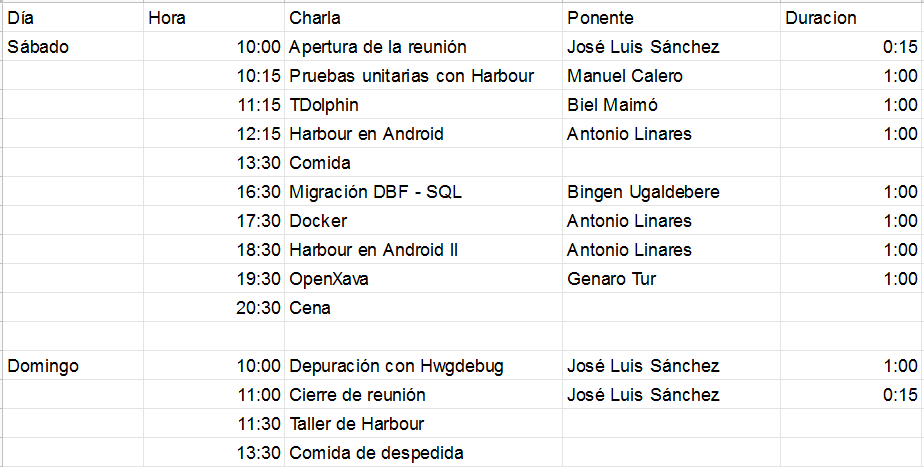
A continuación tienes las presentaciones utilizadas en las charlas de la 2ª Reunión de Harbour Magazine.
Como complemento a mi charla sobre HwgDebug he traducido a español el documento readme.txt que Alexander Kresin incluye con su depurador.hwgdebug.pdfleeme de HwgDebugAlexander Kresin
Esta entrada se publicó originalmente en Harbour Magazine, mi publicación sobre el lenguaje de programación Harbour.
Ya tenemos la relación de charlas para la 2ª Reunión de programadores de Harbour Magazine que vamos a realizar en Calpe los próximos 30 y 31 de Marzo. La agenda es la siguiente:
Las charlas se realizarán en el Campus d’excelencia empresarial Casa Nova de Calpe, desde aqui quiero agradecer al Ayuntamiento de Calpe su colaboración en la organización de la reunión.
Esta entrada se publicó originalmente en Harbour Magazine, mi publicación sobre el lenguaje de programación Harbour.
Harbour Magazine organiza la 2ª Reunión de Programadores en Calpe (Alicante — España) los próximos días 30 y 31 de Marzo de 2019.
En la reunión tendremos una visita turística a la ciudad, conferencias de destacados programadores y mesas redondas. El idioma de la reunión será el español. Las conferencias previstas en el momento de abrir la inscripción son las siguientes:
Pruebas Unitarias en Harbour, por Manuel Calero Solís.
TDolphin, por Biel Maimó.
Migración rápida de DBF a SQL, por Bingen Ugaldebere.
En caso de que algún asistente desee realizar una conferencia puede comunicarlo en el formulario de inscripción.
Este año tenemos previsto dedicar un tiempo a un taller Harbour, donde los asistentes puedan interactuar entre ellos preguntando por cuestiones prácticas de programación. Las ponencias se realizarán en el Campus d’Excel·lència Empresarial Casa Nova.
No hay cuota de registro a la reunión, pero cada asistente deberá costearse su alojamiento. La organización recomienda a los asistentes los siguientes alojamientos:
Esta entrada se publicó originalmente en Harbour Magazine, mi publicación sobre el lenguaje de programación Harbour.
Después de muchos meses de contactos y negociaciones es para mi un honor presentar el proyecto hbuGUI, la GUI multiplataforma unificada para Harbour. El proyecto, impulsado desde Harbour Magazine, ha conseguido crear un consenso entre muchos integrantes de la comunidad Harbour que a partir de ahora van a abandonar sus desarrollos propietarios para volcarse en el nuevo proyecto que tendrá licencia open source.
hbuGUI toma como base el proyecto hbui comenzado por Rafal Jopek para desarrollar un auténtico GUI multiplataforma para Harbour, contando con la participación, entre otros, de los siguientes desarrolladores: Przemyslaw Czerpak, Viktor Szakats, Alexander Kresin, Rafa ‘thefull’ Carmona, Antonio Linares, José F. Gímenez, Ignacio Ortíz, Roberto López, Grigory Filatov, Ron Pinkas, Patrick Mast, Teo Fonrouge, Manu Expósito y Manuel Calero. Cada uno de ellos aportará el conocimiento previo adquirido en el desarrollo de sus propios productos propietarios para contribuir al desarrollo de hbuGUI.
Para el primer trimestre del próximo 2019 está previsto que se libere el código de la versión 1.0 del nuevo GUI que contará con los siguientes elementos principales:
editor + IDE propio multiplataforma
doble jerarquía de clases para facilitar la herencia y los cambios a medida
motor de informes basado en fastreport
acceso nativo a BBDD relacionales basado en HDO
acceso a MongoDB
gestor de pruebas unitarias
ORM propio basado en Eloquent
y todo lo que puedas pedir a sus majestades los Reyes Magos de Oriente
Si has leído hasta aquí debes saber que en España hoy es el día de los inocentes, y evidentemente esto es una broma. Aunque más que una broma es un deseo, el de contar con un único GUI para Harbour que permita que continue el desarrollo de nuestro amado lenguaje y salga del atasco en el que se encuentra ahora.
¡ Féliz Navidad y que el 2019 nos traiga muchas novedades relacionadas con Harbour !
Esta entrada se publicó originalmente en Harbour Magazine, mi publicación sobre el lenguaje de programación Harbour.
Este es un artículo de Quim Ferrer para Harbour Magazine.
Introducción
Aquellos que venimos desarrollando aplicaciones, programas o utilidades desde hace ya algún tiempo, tendemos -algunos- a dejar para el final, casi después de la documentación, el tema de la traducción de nuestros programas a otros idiomas.
Excusas como ya lo haré (futuro inconcreto), no tengo aún demanda o es muy costoso en tiempo y recursos, son por lo general las motivaciones para posponer ‘sine die’ el tema de la traducción.
Desde hace bastante tiempo, existen herramientas generalmente del mundo GNU como es gettexthttps://www.gnu.org/software/gettext que nos han facilitado la transición por el mundo de las traducciones, organizando el trabajo a realizar, para que pueda ser multidisciplinar y colaborativo.
Las GNU Tools nos permiten automatizar tareas para nuestros desarrollos, principalmente :
Extraer cadenas alojadas en variables de nuestro código fuente
Agrupar dichas cadenas como definiciones en una plantilla
Generar a partir de la plantilla anterior un archivo para cada idioma a traducir
Obtener un archivo binario resultado de la compilación de los archivos de traducciones
A nivel técnico, el sistema de traducciones GNU-gettext se basa en la construcción y mantenimiento de los siguientes tipos de archivos :
POT. Plantilla de objeto portable. Archivo que se obtiene cuando se extraen textos de una aplicación. Es el formato de texto para enviar a los traductores.
PO. Objeto portable. Archivo de texto recibido de los traductores. Incluye los textos originales y su correspondencia con las traducciones.
MO. Objeto Máquina. Archivo compilado (binario) obtenido a partir del archivo *.po para cada idioma de la traducción.
El uso de este sistema de traducciones gettext de forma masiva por parte de sitios web multilingües, ha facilitado la adopción ‘de facto’ como un estándar de traducción para varios lenguajes de programación, por ejemplo en PHP.
Antecedentes
Uno de los principales problemas para la difusión (o evangelización) de Harbour es la falta de documentación ‘comprensible’ para su público potencial. Los excelentes desarrolladores de Harbour dotan al compilador de funcionalidades increíbles en relación a una audiencia que considera Harbour una mera ‘traducción’ del CA-Clipper de los años 90. Pero estas ‘extensiones’ fabulosas, no llegan a veces, a sus potenciales usuarios.
Normalmente buscar este tipo de información requiere seguir muy de cerca el grupo de desarrollo de Harbour y profundizar en su código fuente.
Una de las primeras aproximaciones que descubrí para abordar el tema de las traducciones en Harbour, fué el excelente trabajo de investigación de José Luis, editor de Harbour Magazine en una entrada de su blog https://alanit.com/2003/07/i18n-en-xharbour
En aquellos tiempos xHarbour disponía de las primeras herramientas para la internacionalización y en dicho blog, se describe la problemática desde el punto de vista del desarrollador en Harbour que además, quiera utilizar recursos en forma de *.rc, *.dll, etc.
José Luis nos comenta una herramienta llamada hbdict.exe, que es la encargada de extraer los literales tratados con la función i18n. De dicha herramienta, no tengo constancia que esté portada a Harbour ni podamos disponer de ella, si alguien dispone de información, será un placer incluirla en esta documentación.
El siguiente trabajo de investigación me lleva a la guía de uso de la utilidad make de Harbour, llamada hbmk2.exe. Leyendo los innumerables flags de que dispone, presto atención a dos opciones significativas :
-hbl[=<output>] nombre-de-archivo .hbl resultante. macro %{hb_lng} es aceptada en nombre-de-archivo.
-lng=<languages> lista de idiomas a ser reemplazados en %{hb_lng} macros en archivos .pot/.po y nombres de archivos y salida .hbl/.po. Lista separada por comas: -lng=en,hu-HU,de
En este punto es donde me doy cuenta por primera vez la relación entre Harbour y los formatos pot/po. La conclusión es evidente, Harbour no trata con el formato compilado *.mo ya que dispone de su propio formato, el *.hbl (HarBour Language?) A nivel binario son muy parecidos y desconozco el motivo por el cual los desarrolladores de Harbour optaron por un formato propio y no producir el formato estándar *.mo
Para utilizar otros sistemas make, harbour/bin dispone de la utilidad hbi18n.exe que también es capaz de generar salida *.hbl a partir de *.po
Cómo puede Harbour aprovechar GNU-gettext ?
Con esta pequeña guía, pretendo facilitar la labor a otros desarrolladores que quieran implementar multilenguaje en sus aplicaciones.
Para empezar, definimos una macro para poder implementar cambios globales de forma unitaria. En este ejemplo, transformo también la cadena a UTF8
#define _txt( x ) hb_UTF8ToStr( hb_i18n_gettext(x) )
Preparar nuestro código Harbour
@ 2,1 SAY _txt(“Editar”)
En Fivewin :
REDEFINE SAY VAR _txt(“Editar”) ID 200 OF oDlg
Compilar fuente para obtener salida en formato *.pot
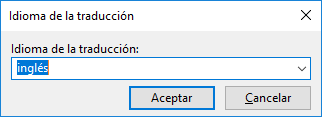
Ejecutar poedit y crear nueva traducción, Archivo-> Nueva desde archivo POT/PO. La primera vez que ejecutemos poedit, nos pedirá el idioma base de traducción.
Elegir la plantilla app.pot generada en el proceso de compilación de Harbour. Poedit nos pregunta por el idioma de traducción
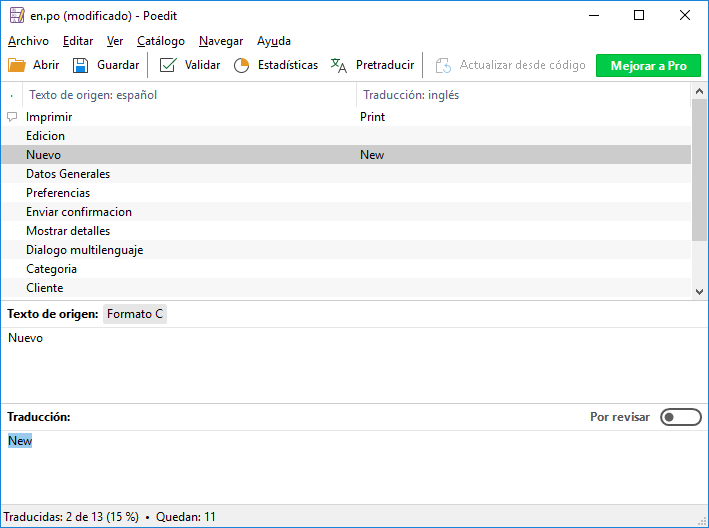
Empezar con las traducciones:
Guardar traducción, por ejemplo para idioma inglés en.po
Vemos que también genera el archivo *.mo que no vamos a utilizar
Una vez finalizada(s) la(s) traducción(es) es el momento de generar el binario del idioma o idiomas que cargaremos en nuestra aplicación. Para ello disponemos del superpoder de hbmk2.exe, utilidad make de Harbour.
hbmk2 -hbl en.po
La utilidad crea el archivo en.hbl a partir de en.po
Ya sólo nos queda implementarlo en nuestra aplicación :
Con este procedimiento, todos los literales en código fuente quedan traducidos y si queremos cambiar de idioma en tiempo de ejecución, basta con apuntar a otro set de idioma, llamando a las instrucciones anteriores.
Cada vez que exista un cambio en nuestro código, solamente habrá que generar de nuevo el archivo de plantilla *.pot, abrir cada archivo de idioma *.po y desde la opción del menú de poedit, Catálogo->Actualizar desde archivo POT. Los cambios anteriores permanecen intactos y las nuevas entradas quedan pendientes de traducir, con facilidad para buscarlas.
Os dejo un enlace a github https://github.com/QuimFerrer/i18n con código de ejemplo y uso de un script make hbmk2, para producir la compilación en múltiples idiomas automáticamente.
Para terminar, os animo a investigar, mejorar y comentar, experiencias que tengáis en la internacionalización y traducción de vuestras creaciones
Esta entrada se publicó originalmente en Harbour Magazine, mi publicación sobre el lenguaje de programación Harbour.
Dentro de las herramientas de trabajo de los programadores, el editor de código ocupa un lugar destacado. Es uno de los programas con el que pasas más tiempo trabajando, de manera que es muy importante sentirte cómodo trabajando con él y también debes conocerlo lo suficiente para ser productivo utilizándolo.
En esta entrada voy a presentar el editor que poco a poco se ha convertido en mi editor preferido, explicaré los motivos por los que lo uso y las extensiones que utilizo, por supuesto orientado a su uso con Harbour. Reconozco que mi interés por Visual Studio Code — VSCode en adelante — fue utilizar los temas oscuros que tiene, motivos meramente estéticos, pero las funcionalidades que incorpora lo han convertido en mi editor favorito. Hay cosas que todavia no conozco bien, como la creación de tareas, pero sigo intentando aprender a utilizarlas.
Antes de continuar quiero hacer un inciso. Si haces software de escritorio debes intentar que tu aplicación tenga un aspecto actual, y para ello debes conocer las aplicaciones actuales. Si usas el Norton Commander y un editor de hace 20 años, no conoces cual es el aspecto de las aplicaciones actuales, con lo que te parece normal usar botones con efecto 3D y esas cosas que tenía Windows XP. Mi recomendación es que uses un editor moderno y VSCode es uno de los más bonitos.
Al hablar de utilizar VSCode y su uso con Harbour lo primero que hay que decir es que debes instalar la extensión de Antonino Perricone para Harbour — aperricone.harbour en adelante — que tienes disponible en https://marketplace.visualstudio.com/items?itemName=aperricone.harbour. Esta extensión facilita enormemente el uso del editor con Harbour como verás a continuación.
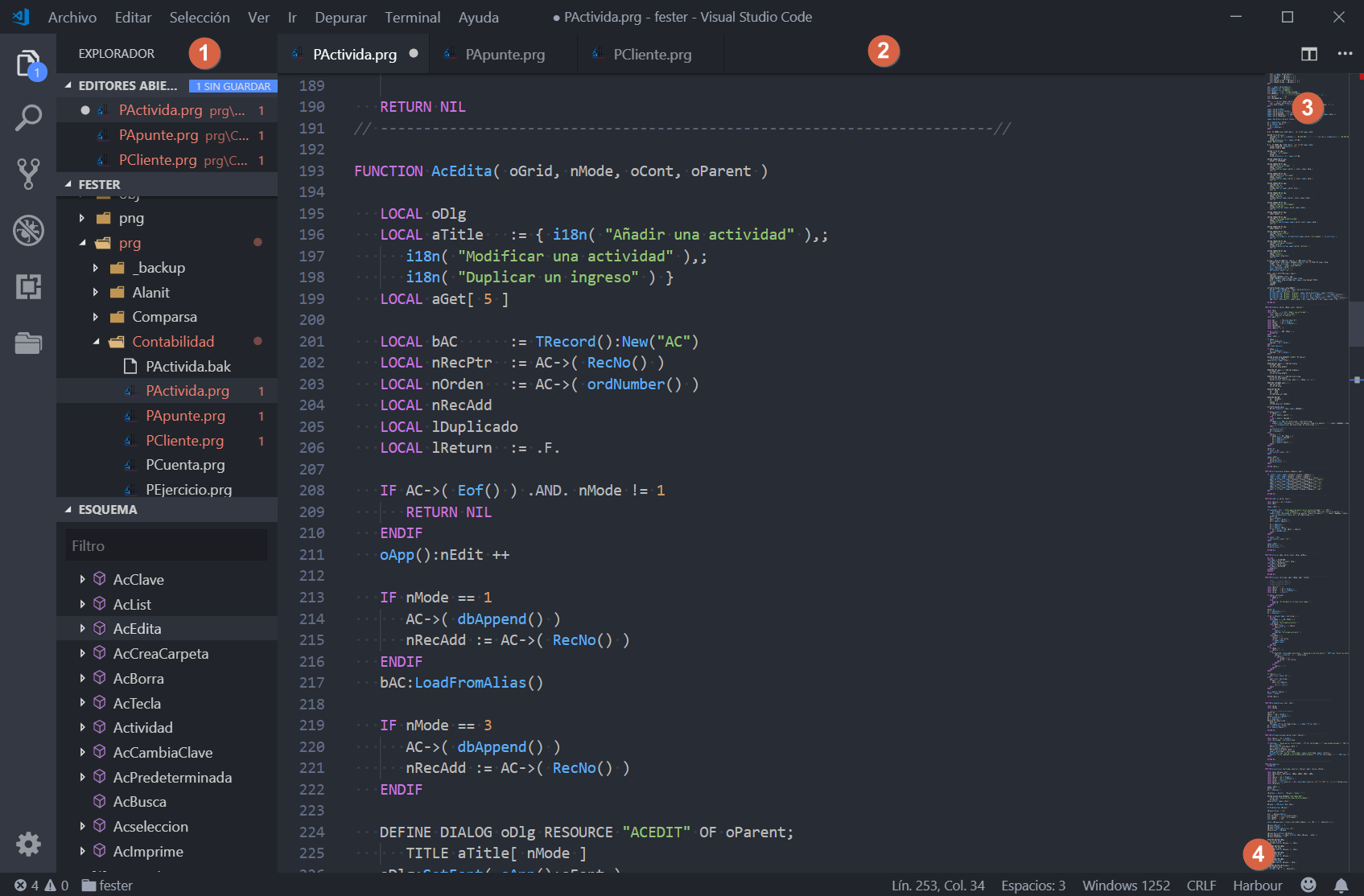
Un aspecto típico de VSCode trabajando con un proyecto Harbour es el siguiente, en el que puedes ver 3 áreas diferenciadas: (1) el explorador de código, (2) la ventana de código, (3) el minimapa y (4) la barra de estado que nos dice que el archivo que estoy editando está usando la extensión de Harbour. El minimapa es algo que llama la atención a primera vista, pero yo no le encuentro apenas uso.
VSCode con la extensión Harbour de Antonino Perricone
Dentro del explorador (1) tenemos la lista de editores abiertos, la carpeta de proyecto que estamos utilizando y la vista de esquema. Esta última la muestra la extensión aperricone.harbour y es una lista de árbol con las funciones o métodos de nuestro archivo .prg y las variables que tengamos definidas en ellas. Este esquema facilita enormemente la navegación en archivos grandes de código.
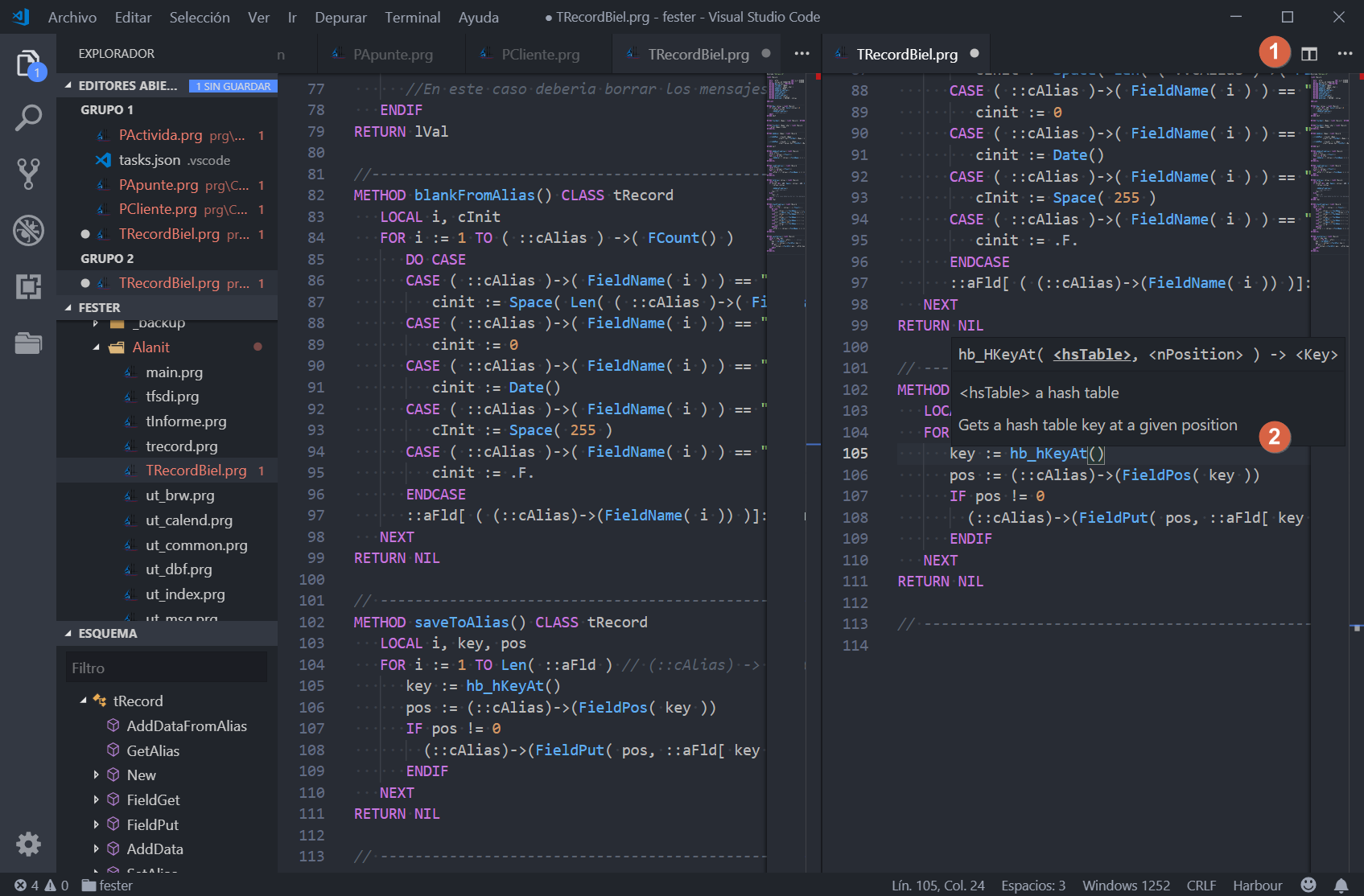
En la ventana de código es donde editaremos nuestro código y tenemos todas las funcionalidades habituales, pero quiero llamar la atención sobre dos cosas que me parecen muy interesantes: (1) la primera es la posibilidad de dividir la zona de edición verticalmente para mostrar al mismo tiempo diferentes o el mismo archivo fuente, y (2) la ayuda que ofrece aperricone.harbour sobre las funciones de Harbour conforme las vamos escribiendo.
VSCode con la ventana de edición dividida y la ayuda de funciones de Harbour
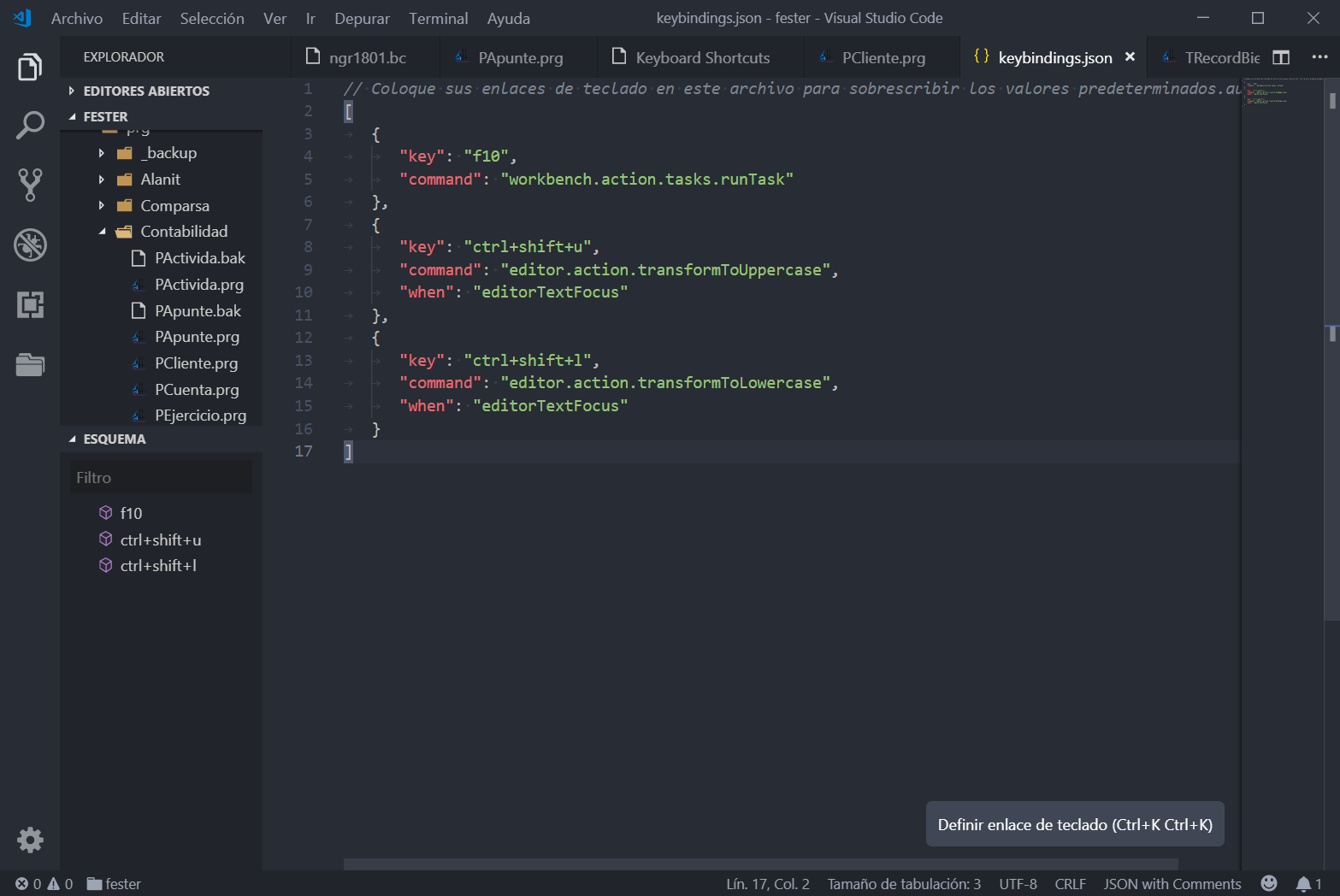
Una de las cosas que me gusta de VSCode es la posibilidad que tiene para añadir funcionalidades extra, y que hay cantidad de información al respecto. Por ejemplo, yo uso mucho la característica de cambiar una palabra a mayúsculas, y VSCode no trae como nativa la manera de hacerlo. Buscando un poco por internet encontré pronto la manera de hacerlo. Entras en Archivo > Preferencias > Métodos abreviados de teclado y tienes que editar el fichero keybindings.json introduciendo lo siguiente:
Definición de atajos de teclado adicionales en VSCode
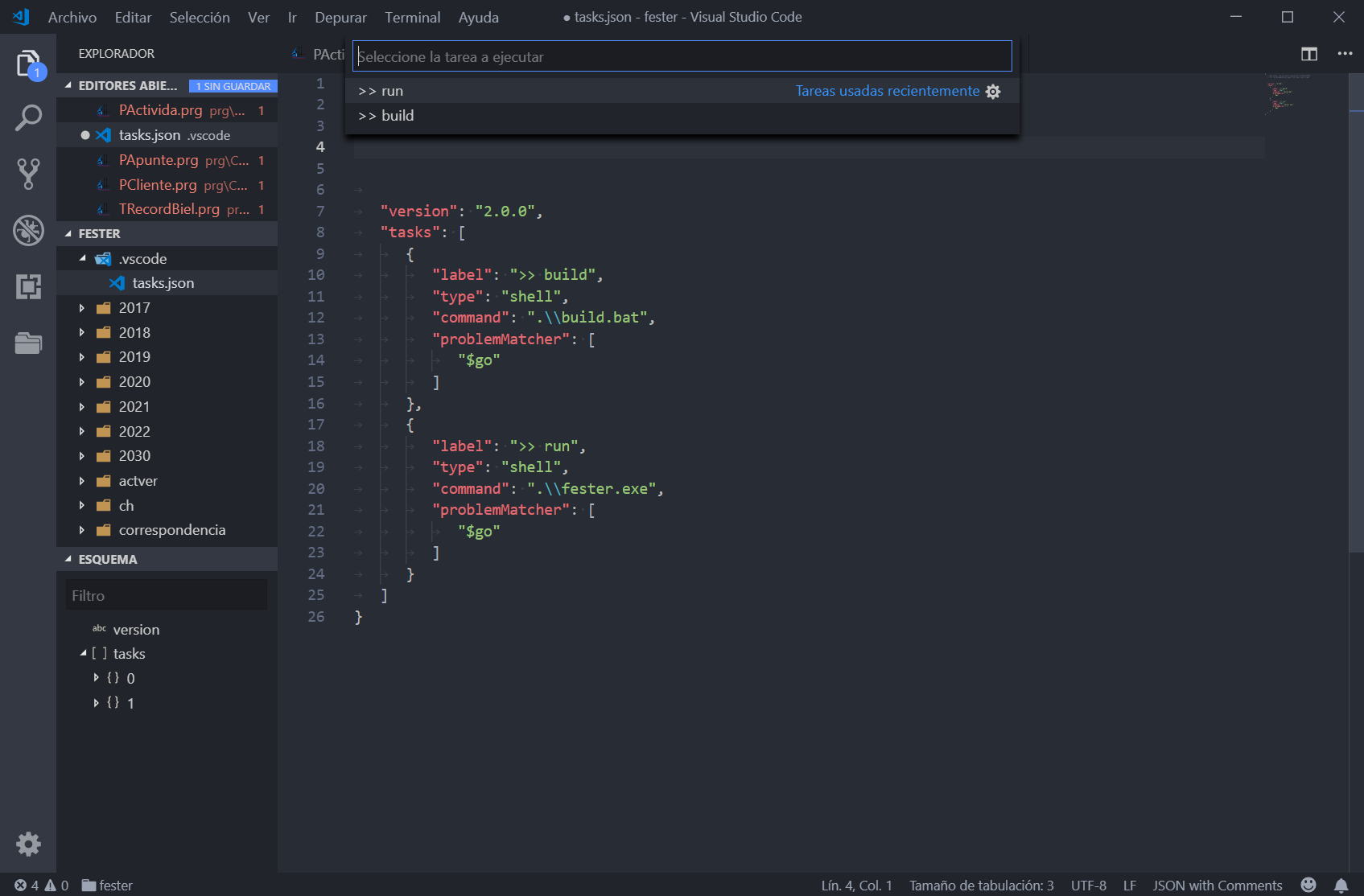
Para compilar y ejecutar tu aplicación tienes que definir tareas. Actualmente utilizo sólo dos tareas, una para compilar la aplicación y otra para ejecutarla. La definición de las tareas es la que muestro a continuación:
Definición de tareas de compilación y ejecución en VSCode
Con esto tengo suficiente para compilar y ejecutar mi aplicación, pero creo que es un uso realmente mínimo de lo que se puede hacer. Se que con la extensión aperricone.harbour se puede depurar la aplicación desde dentro del editor, pero no sé la manera de hacerlo. Espero que Antonino encuentre tiempo para hacer un tutorial al respecto.
Además de la extensión aperricone.harbour utilizo las siguientes extensiones para VSCode:
Espero que tras este artículo te animes a usar VSCode con Harbour, y si ya lo usas y quieres compartir algún truco al respecto espero que lo hagas en los comentarios.