He estado retocando el blog. He puesto la barra de navegación a la izquierda y he añadido algunos detalles estéticos. ¿ Te gustá más ahora ? Realmente MT es una pasada, si haces un blog a mano… ve enseguida a descargarlo.
Viniendo de trabajar iba dándole vueltas a la cabeza a un viejo tema: ¿ donde se debe poner una barra de navegación, a la izquierda o a la derecha ? ¿ Y en un formulario de un programa ?
Ignacio Ortiz de Zúñiga ha realizado una actualización de su xBrowse en que ha incluido dos nuevas funcionalidades en su control.
La primera es la asignación un tooltip a la cabecera de la columna y la segunda la posibilidad de evaluar un codeblock haciendo dobleclick sobre la cabecera de una columna. Necesitaba esto para implementarlo en mi programa de contraseñas, pues quería que se pudiera ordenar las columnas de la rejilla de datos directamente sobre ella. La manera habitual de esto es con click o dobleclick sobre la cabecera, pero el click está asociado en xbrowse al drag & drop de columnas para reordenar, con lo que era necesario tener tambien la posibilidad de usar doble clicl. El click con el botón derecho del ratón sobre la cabecera está asociado a un menú popup que permite mostrar y ocultar las columnas.
Creo que con estas dos nuevas funcionalidades, xbrowse es la rejilla de datos más potente y versatil que existe ahora mismo para usar con xHarbour/FWH.
En su artículo Computer Science: the discipline, Peter Denning hace una interesante descripción de lo que constituye el cuerpo de conocimiento de la Informática. Uno de los puntos que considero más acertados del artículo es el que se refiere a las habilidades básicas que deben tener los integrantes de la profesión y que es especialmente adecuado a los que nos dedicamos a desarrollar software. Estas habilidades son las siguientes:
pensamiento algorítmico: interpretación del mundo reformulada en acciones paso a paso para resolver un problema.
representación: manera en la que los datos son almacenados para ser recuperados eficientemente.
programación: permite tomar el pensamiento algorítmico y la representación para expresarlos en forma de software ejecutable en un ordenador.
diseño: conecta las anteriores capacidades con los problemas de la gente para resolver sus problemas particulares.
¿ Imaginas desarrollar software sin contar con estos conocimientos básicos ?
En el número del mes de abril de la revista PcPlus viene un interesante artículo dedicado a la comercialización de software. Abarca algunos aspectos referidos a esta actividad como el registro de la propiedad intelectual de la obra, canales de comercialización, originalidad del software, etc. Sin embargo el artículo se queda corto para alguien que realmente quiera dedicarse a comercializar su propio software bajo la modalidad de shareware.
Por shareware entiendo un determinado tipo de software que tiene unas características muy concretas:
el software ha sido desarrollado originalmente por su autor para su uso personal
es el propio desarrollador quien ofrece y comercializa este software
existen versiones de evaluación para que el potencial usuario pueda probar el programa y decidir si es lo que busca
la versión completa del programa se puede registrar por un bajo precio, normalmente entre 20 y 50 €
El shareware ha contagiado de algunas de sus características a otros tipos de software. Actualmente casi todos los programas del mercado ofrecen versiones de evaluación y muchos programas comerciales han bajado los precios ante la competencia de aplicaciones shareware, sin embargo no son – desde mi punto de vista – aplicaciones shareware.
La comercialización de shareware obliga al desarrollador a enfrentarse con temas que antes nunca habia considerado. Partiendo de que ya contamos con un programa terminado y registrado, veamos cual es el camino a seguir.
En primer lugar se debe realizar la documentación adecuada del programa, aspecto que no suele agradar mucho a los programadores. Una buena documentación en formato electrónico es imprescindible, si bien una gran parte de usuarios jamás la leerá y preferirá preguntar directamente al autor cualquier duda que tenga sobre el mismo.
La promoción del programa se debe intentar por todos los medios al alcance del desarrollador. Una posibilidad es enviar el programa a todas las revistas conocidas con la esperanza de que publiquen una referencia o una versión de evaluación sobre la misma. Aquí la suerte es dispar, mientras que hay revistas que tienen buena disposición a la publicación de shareware hay otras en que es practicamente imposible conseguirlo. El siguiente paso suele ser contactar con empresas editoras de software, pero es muy difícil entrar en ese mercado. Si el programa no es muy bueno lo rechazarán sin tan siquiera contestar y si es bueno habrá que entrar a negociar la venta. Esta negociación será muy dura pues las empresas editoras querrán normalmente cerrar un precio para hacerse con los derechos del programa.
Dejo para el final la obligatoria creación de la página web del programa. El desarrollador tendrá que enfrentarse a elegir su nombre de dominio, diseñar su página web, contratar alojamiento, ofrecer multiples modalidades de pago y promocionar su web en los portales dedicados a shareware compitiendo con software comercial.
En la mayoría de casos que conozco de desarrolladores de shareware, toda esta actividad la realiza una única persona y ahi es donde radica el problema. La mayoría de programadores son buenos o muy buenos programando, pero no son capaces de recorrer todo el camino para llegar a comercializar su software. El bajo precio del shareware hace que unicamente se obtengan beneficios si el volumen de ventas es grande, cosa que por otra parte es muy dificil que llegue a suceder.
Una vez hecho todo esto es cuando realmente comienzan los dolores de cabeza: correos preguntando lo que está en la documentación, preguntando lo que vale el programa o como pagarlo, errores que les surgen a potenciales usuarios,… Este es el momento en hay que trabajar y ganarse a cada usuario en cada correo y en cada llamada. Y sobre todo no desfallecer y mandarlo todo a paseo.
He dejado al margen los temas laborales y fiscales de la actividad económica, pero al inicio de la actividad hace falta darse de alta en la seguridad social, registro de actividad económica, IVA,…
En el artículo que mencionaba al principio se alude a la escasez de buen software en castellano. Creo que después de lo expuesto es más facil de entender.
Una de las cosas más complicadas que se han de decidir cuando se aborda el desarrollo de un sitio web es la elección de un nombre. A esta actividad los americanos, que tienen nombre para todo, le llaman naming. Hay incluso empresas que se dedican a hacer naming para terceros, el caso más llamativo quiza sea HundredMonkeys.
En uno de los últimos post de mi antiguo blog decía que el dominio para este blog era uno muy bueno. ¿ Es el nombre avemundi adecuado para un blog sobre desarrollo de software ? Desde mi punto de vista si. El primer programa que se hace en casi todos los libros de programación es Hola mundo que en latín es … avemundi.
Hoy inauguro este blog. La temática principal va a ser desarrollo de todo tipo de software, desde aplicaciones shareware – el segmento en que desarrollo mis aplicaciones – al desarrollo web – en el que estoy comenzando. Este blog va a ser continuación de software*, pero posiblemente sea un blog colectivo.
Mis preferencias dentro del desarrollo son los lenguajes xBase, actualmente uso Clipper/Fivewin y estoy migrando mis aplicaciones a xHarbour/FWH. También me interesan mucho los gestores de contenidos para sitios web, y estoy utilizando MovableType para hacer este sitio. En cuanto al desarrollo web, utilizo PHP y MySQL.
Mi intención no es hacer un weblog técnico, sino comentar otros temas relacionados con el proceso de desarrollo del software a las que muchas veces no se le presta la debida atención. Quiero incluir enlaces a sitios web interesantes, recomendaciones de artículos y libros, experiencias personales,… un poco de todo.
La refactorización en Programación Extrema consiste en la revisión continua del código para mejorar su legibilidad, evitar duplicaciones, hacerlo más eficiente y más facilmente modificable. Para una introducción a la Programación Extrema ver el post de 30.ago.2002 de este weblog.
Estos dias estoy migrando Guardian a Harbour y mi buen amigo Manuel Calero me explicó la técnica del uso de arrays de controles en dialogos de edición de datos. La idea es que en vez de tener un montón de objetos GET, meterlos todos dentro de un array de get’s de manera que sea más fácil su manipulación.
código a refactorizar
En mis programas uso una indicación de que el registro que está en edición se ha modificado. Esta indicación se realiza mediante un bitmap colocado en el extremo inferior del dialogo que cambia de color cuando se modifica cualquier campo del dialogo. Al entrar a editar el dialogo el bitmap se encuentra atenuado y en cuanto se modifica cualquier campo el bitmap cambia y muestra un color más vivo.
Para ello, en cada GET tenía definida el evento bChange de manera que llamaba a una función que cambiaba el bitmap a mostrar. Algo asi:
REDEFINE GET oGet05 VAR cClUsuario ID 105 OF oDlg oGet05:bChange := { || HaCambiado( oBmp ) }
y luego la función que cambiada el bitmap:
Function HaCambiado(oBmp) oBmp:Reload( 'CLIP_ON' ) oBmp:refresh() Return NIL
El problema de esto era que si el dialogo tenía 20 gets, tenía que tener 20 veces el dichoso oGet:bChange definido.
Refactorización
Lo primero que hice para refactorizar fue definir un array vacio de 20 elementos, tantos como GET tenía mi dialogo. Después redefiní los get a la manera habitual, pero cada get no era un objeto sino un elemento del array de GET:
LOCAL aGet [20] ... REDEFINE GET aGet[02] VAR cClUsuario ID 102 OF oDlg
La gracia está en la manera de hacer el cambio del bitmap cuando cualquier objeto GET cambia. Ahora esto se hace en una sola linea de código usando AEVAL:
Joaquín Hernández Márquez Trabajo realizado para la asignatura Historia de la Informática y Metodología de la Ciencia Reproducido con autorización del autor 24.ene.2003
El término de lenguajes xBase nace de un sistema de gestión de bases de datos llamado dBase, que en los años 80 y 90 dominó el mercado de las bases de datos. Este éxito dió lugar a una serie de herramientas y productos que imitaban su forma de manejar tablas de datos mediante una serie de comandos interactivos que pasaron a agruparse en programas, constituyendo así un autentico lenguaje de programación.
Los orígenes.
La historia de dBase comienza en 1970 con un sistema llamado RETRIEVE. RETRIEVE era comercializado por Tymsahre Corporation y se usaba en el Jet Propulsion Laboratory de Pasadena, en California, como base de datos. Era un programa muy rudimentario, corría sobre una UNIVAC 1108 y contaba con sólo 5 comandos : Create, Delete, List, Modify y Append.
En 1971 Jeb Long y Jack Hatfield, basándose en RETRIEVE, comenzaron a desarrollar un sistema de base de datos más potente. Jack Hatfield dejo el JPL tiempo después pero Jeb Long terminó la tarea. El programa se llamó JPLDIS, Jet Propulsion Laboratory Display Information System, estaba escrito en FORTRAN sobre una UNIVAC 1108 y contaba con 50 comandos. JPLDIS se usó no sólo en el JPL, sino también en otras agencias gubernamentales.
En 1975, Wayne Ratliff trabajaba en la Martin Marietta Corporation (una importante contratista de la NASA) desarrollando un sistema de manejo de datos llamado MFILE, el cual sería utilizado en la nave VIKING en su viaje a Marte en 1976. En este momento empezó a interesarse por dos cosas : el procesamiento del lenguaje natural y el fútbol americano. Ratliff intentó aplicar sus conocimientos para realizar un programa con el que analizar las estadísticas de los resultados del fútbol pero la tarea le fué imposible. Se dió cuenta de que no tenía el programa adecuado y se propuso crear un sistema de bases de datos con una interfaz en lenguaje natural.
En 1978 y tomando como base JPLDIS, Ratliff empezó un programa al que llamaría Vulcan. Escrito enteramente en lenguaje ensamblador, se ejecutaba sobre una IMSAI 8080 con un sistema operativo PTDOS, aunque despu´s crearía un versión sobre un sistema operativo más difundido en ese momento: el CP/M. En Octubre de 1979, un año y nueve meses después, Ratliff colocó un anuncio en la revista BYTE poniendo a la venta su recien acabado programa, Vulcan llegaba al mercado.
Vulcan no era el único programa de su tipo, existían otros como FMS 80, Condor o Selector, en el verano de 1980 se habían vendido 60 copias de Vulcan. Ratliff, al mismo tiempo que seguía trabajando en Martin Marietta atendía los pedidos, de hecho era él mismo el que rellenaba las facturas, hacia las copias en disquetes y enviaba el programa por correo. Esta situación era demasiado agotadora y decidió retirar los anuncios de las revistas, no vender más Vulcan y únicamente dar soporte a las copias ya vendidas. En este momento, Ratliff empezó a entablar negociaciones con un profesor de la universidad de Washington y su esposa, que se interesaron por la comercialización del programa, fue entonces cuando llegaron los propietarios de una pequeña empresa de distribución llamada Discount Software, George Tate y Hal Lashlee. Tras presenciar una demostración de Vulcan se decidieron apostar por el producto, firmaron con Ratliff un contrato de distribución y dio comienzo la andadura de dBase.
El imperio dBase.
Tras adquirir los derechos de comercialización, George Tate tomo el control sobre el marketing de su nuevo producto y lo primero que hizo fue cambiarle el nombre, en parte porque buscaba un nombre más serio y en parte porque una empresa de Florida distribuía un sistema operativo con ese mismo apelativo. Así pues, Tate eligió la denominación de dBaseII (dBaseI nunca existió) y para comenzar a venderlo también cambio el nombre de su compañía a Asthon-Tate, al parecer porque le sonaba mejor que Tate-Lashlee (Asthon era el nombre de su periquito!?).
En febrero de 1981, dBaseII comenzó a ser un éxito de ventas, se vendía a 650$ US y para finales de ese mismo año, Ratliff tubo que contratar a varias personas para poder realizar las modificaciones que le pedían los clientes. A mediados de 1982 se vendía tan bien que dejó su empleo para dedicarse íntegramente a dBase. dBaseII era un producto único en su época, potente pero sobre todo muy fácil de aprender por el usuario final (en contraste con otros lenguajes como C, Cobol o Basic). Asthon-Tate publicó el formato de ficheros de dBase, el DBF y multitud de programas eran capaces de leerlo, contribuyendo así a su cada vez mayor difusión.
En 1983 Ratliff vendió los derechos íntegros de dBase y pasó a ser Vicepresidente de Nuevas Tecnologías, en ese mismo año apareció la versión 2.4 para PC’s (con PC_DOS) y Ratliff cansado de problemas se tomó un descanso en el que retomó su pasión por la IA. Fue un descanso corto, ya que presionado por la aparición de otros competidores (como R:BASE), Ratliff volvió para sacar a luz una nueva versión más rápida de dBase. Así y en sólo cuatro meses, en Junio de 1984, apareció dBaseIII, escrito ya en C y para procesadores de 16 bits, después de esto volvió a su aislamiento. Mientras se publicaba la versión dBaseIII Plus, que incluía un nuevo interfaz de menús desplegables Assist (al estilo de WordStar, el entonces mejor procesador de textos).
En Agosto de 1984 moría de un ataque al corazón George Tate y con el empezó a desvanecerse la magia de dBase. Ed Esber, (ex-vicepresidente de mercadotecnia de Visicorp) tomó el mando de Ashton-Tate, pero las cosas sólo empeoraron. Esber inclinó la balanza demasiado al lado de la mercadotecnia, olvidándose de la tecnología. En enero de 1986, Ratliff abandonó la empresa y a dBase.
El comienzo del fin.
En 1985 las cosas ya no iban tan bien. Debido al enorme éxito de dBaseIII+ comenzaron a aparecer productos que lo imitaban e incluso le superaban en algunos aspectos. Paradox, Quicksilver, Arago, dBXL y Clipper, que contaban con la gran ventaja que compilaba los programas produciendo un ejecutable (con la consiguiente ganancia de velocidad y salvaguarda del código fuente).
En 1988, por fin apareció dBaseIV 1.0, incluía numerosos avances : ventanas, menús, la capacidad de Rollback, muchas nuevas funciones.. pero sobre todo aparecía con dos años de retraso, sin compilador de programas y ¡lleno de errores! Un año y medio esperaron los usuarios hasta que salió la versión que corregía los errores, la 1.1. dBase perdió una gran cuota de mercado en ese tiempo y sus competidores se hicieron más grandes. Además, en 1990 Microsoft presentó su Windows 3.0, producto que fue un auténtico éxito. Pero dBase no conseguía adaptarse y seguía siendo un programa bajo DOS. Ese mismo año y tras unos resultados económicos bastante malos, Esber abandonaba el barco.
En 1991, una entonces pequeña compañía llamada Borland dio la sorpresa al comprar dBase a Ashton-Tate y en 1993, de su mano, aparecía la versión 2.0 de dBaseIV, una versión muy estable y que por fin traía el ansiado compilador. Sin embargo era ya demasiado tarde, WordTech había presentado Arago for Windows, era dBase para Windows pero mejor que el propio dBase. Borland se vio entonces forzada a comprar Arago y éste programa sería el corazón de dBaseV for Windows, que sería presentado en Agosto de 1994. Este fue el final del dBase original, ya que en la nueva versión lo único que se había salvado de él era el debugger.
En Julio de 1995 saldría la mercado Visual dBase 5 y en Diciembre de 1997 Visual dBase 7, una versión ya totalmente de 32 bits que corría bajo Windows95 y NT. Sin embargo dichas versiones estaban ya destinadas a un público profesional, de desarrolladores. Se había perdido definitivamente el espíritu de fácil manejo y asequible al usuario final que llevo a dBaseII a dominar el mercado de su época como pocos productos lo han hecho en su categoría.
Ashton-Tate versus tenología xBase.
Desde el éxito de dBaseII numerosos productos habían salido al mercado intentando copiar su modelo de programa, pero sobre todo se copiaba aquello que había lo había hecho triunfar: su sencillo, y a la vez potente, interfaz de comandos, los cuales constituían un verdadero lenguaje de programación.
Lógicamente, viendo como sus competidores le comían terreno día a día, Ashton-Tate intento controlar su criatura y la forma que tenía de hacerlo era mediante denuncias. Ashton-Tate denunciaba a todos aquellos productos que hacían referencia a dBase y/o copiaban de alguna manera su producto y así nació el término xBase.
En Septiembre de 1988, una de estas denuncias cayó sobre Fox Software y su producto FoxBASE. Dos años más tarde, en 11 de Diciembre de 1990, el juez Hatter dictó una sentencia que condenaba a dBase: según Hatter, Ashton-Tate habían intentado ocultar que dBase procedía de un programa público, JPLDIS, y que por lo tanto no podía intentar ejercer derechos de copyright sobre él, en consecuencia y como condena, permitía a cualquier compañía copiar su interfaz, era sin duda la derrota de dBase como producto y la victoria de xBase como tecnología.
Dialectos xBase I : Clipper y CA-Clipper.
Si tomamos el conjunto de comandos de dBase como un lenguaje, los diversos productos que lo implementaban estaban creando una serie de dialectos que normalmente ofrecían compatibilidad con el dBase original (como mínimo con dBaseII y III) y luego una serie de “extras” en formas de nuevas funciones y capacidades.
Uno de estos primeros dialectos que consiguió una gran difusión fue Clipper. Clipper apareció en 1985 de la mano de una empresa denominada Natuncket, se ofrecía como un compilador de programas dBase. Escrito en C y en ensamblador, producía programas ejecutables que podían funcionar de forma independiente y sin necesidad de ningún tipo de run-time. Existían cinco versiones del Natuncket Clipper original : Clipper’85, Clipper86, Clipper’87, Clipper 5.0 y Clipper 5.01 esta última publicada en Abril de 1991.
En 1992 la empresa Computer Associates compró Clipper y en Febrero de 1993 presento CA-Clipper 5.2, surgieron varias versiones más y en Mayo de 1996 se publicó la última en el formato tradicional de compilador para DOS, la CA_Clipper 5.3. En estos momentos si se querían hacer programas para Windows con Clipper se podían utilizar librerías como FiveWin o Clip4Win, estas estaban desarrolladas por empresas que nada tenían que ver con CA, la cual presentaría su propuesta para Windows en forma de CA Visual Objects. Este era un entorno de programación que paradójicamente no acabó de cuajar entre la comunidad de desarrolladores, ya que CA-VO imponía más bien un nuevo modo de programación. El resultado fue que muchos desarrolladores siguieron programando en el Clipper clásico y utilizando dichas librerías para portar sus programas a Windows.
Dialectos xBase II : FoxPro.
Siguiendo la estela de Windows, otro dialecto xBase era FoxPro. Este producto había nacido en 1984 de la mano de Dave Fulton y Bill Ferguson bajo el nombre de FoxBase. FoxBase era un compilador de dBaseII que creaba ejecutables bastante rápidos y eficientes. En Junio de 1986 salía al mercado FoxBASE+ y en 1988 Fox Software recibía una demanda de Ashton-Tate. Sin embargo su desarrollo no se paró, y en 1989 apareció FoxPro 1.0, la primera versión que abandonaba el DOS en favor de Windows. En Julio de 1991 y ya publicada la sentencia absolutoria, aparece FoxPro 2.0 cuyo mayor logro fue la inclusión de la tecnología Rushmore, un método de acceso a registros muy eficiente que aceleraba considerablemente los programas escritos con Fox. Además, se añadió el lenguaje de datos SQL.
En Junio de 1992 se produjo un hecho que pocos esperaban, Microsoft adquiere FoxPro por 173 millones de dólares (un hecho singular ya que en ese momento existía un proyecto llamado Cirrus que más tarde daría lugar a un SGBD llamado MS Access). Inmediatamente se publica MS FoxPro 2.0 cuyo única diferencia consiste en el logotipo de Microsoft en la caja del producto. Microsoft distribuyó varias versiones más de FoxPro, la versión 2.5 aparece en Enero de 1993 y siguiendo la política de MS nuevos parches aparecen cada 2 o 3 meses para tapar los fallos, son la versiones 2.5a y 2.5b. En Marzo de 1994 llega FoxPro 2.6 que promulga una mayor compatibilidad con dBase e incluye por primera ver diversos Wizars. En 1995 se produce un hecho importante, Dave Fulton abandona Microsoft. Salen varios parches más hasta Julio 1999, momento en que MS anuncia que dejará de dar soporte a FoxPro 2.x, pasando a incluirlo en su lista de productos obsoletos y centrándose en Visual FoxPro como su sucesor natural hasta el momento actual.
Actualmente Visual FoxPro sigue en el «candelero». Forma parte de Visual Studio y MIcrosoft parece tenerlo en cuenta en su estrategia de mercado. Hay que recordar que VFP fue desde el principio diseñado para manejar datos y para manejarlos bien.
Dialectos xBase III : Alaska xBase++.
XBase++ es un compilar de Clipper para entornos gráficos. Es compatible con el lenguaje definido en CA-Clipper hasta la versión 5.2e. xBase++ se centra el una fácil migración de aplicaciones escritas en Clipper (se requieren pequeños cambios para lograr la compatibilidad con dBASE o FoxPro), sobre todo a entornos gráficos como Windows 95, NT e incluso OS/2. Así si en CA-Visual Objects se tenía la gran desventaja de tener que escribir bastante código nuevo para adaptarnos a los nuevos controles gráficos, xBase++ propone un modelo de eventos que hace esta transición mucho más directa.
Además, los ejecutables generados son netamente de 32 bits, con las mejoras de rendimiento y potencia que ello conlleva (no genera para DOS ni para Win 3.x). El código generado es código nativo y no el conocido pseudocompilado de Clipper. Incluye además su propio compilador y enlazador de 32 bits, que a parte de generar ejecutables es capaz de generar DLLs. Permite también la ejecución multiproceso mediante el uso de hebras concurrentes.
Free xBase.
Relacionados con xBase existen varios proyectos que siguen una política de libre distribución. Son intentos de dotar a la comunidad xBase de herramientas de libre uso o gratuitas, que permitan el desarrollo de proyectos en estos lenguajes.
Sin duda el más interesante es el Proyecto Harbour. Este es un proyecto de desarrollo de un compilador para el lenguaje xBase, que se fundamenta en dar compatibilidad con la versión de CA-Clipper 5.2 Internacional. El compilar es multiplataforma, es decir, existen versiones para Windows 95, 98, 200, NT, MSDOS, Linux y FreeBSD.
Otro proyecto es X2C, este es un compilar de xBase que genera ejecutables mediante el paso intermedio de creación de un programa en C equivalente al fuente. Admite los dialectos dBaseIII+, Clipper’87 y FoxBASE 2.1.
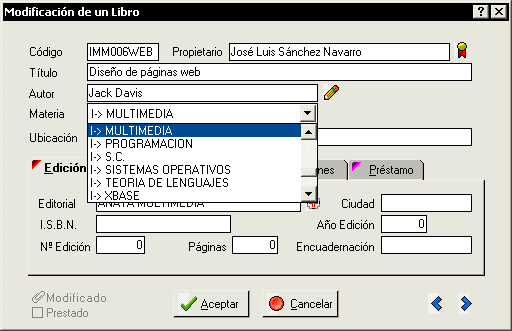
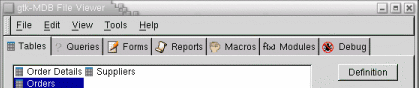
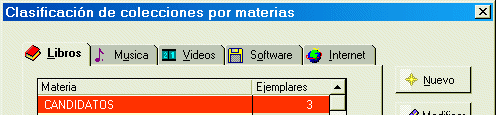
Un combobox o cuadro de lista desplegable es un control en que el usuario introduce o elige un valor de una lista para un campo determinado. Se suele usar cuando el campo corresponde a una clave ajena el fichero en que estamos y a menudo se restringe la introducción manual del valor dejando unicamente la selección del valor a introducir de la lista. Si se carga la lista con los posibles valores de la clave ajena, nos ahorramos la validación del campo pues unicamente dejamos al usuario introducir valores posibles. Un ejemplo de combobox se muestra en la siguiente figura:
Yo utilizaba comboboxes cuando el campo en cuestión era obligatorio al rellenar el formulario, como en este caso la matería del libro. Sin embargo los combos tienen un problema tremendo: ¿ Que pasa cuando el usuario desea introducir un valor que no está en la lista ?. Se también la solución que más de uno está pensando: Quitas la restricción de usar unicamente la lista y dejas que el usuario pique lo que quiera. Demasiado fácil. Si hago esto y el usuario mete un valor para el campo materia que no está en la lista, que hago con este valor ¿ darlo de alta en el fichero de materias ? Y si lo hago ¿ cómo se lo digo al usuario ? ¿ Quedará claro ? Siempre que he visto en un libro ejemplos de combos se hacen sobre datos estáticos, como provincias, estados, etc. Nunca se hacen sobre datos que puedan ser susceptibles de cambiar dinamicamente.
Además en la figura superior se ven unos bitmaps al lado de los campos Autor y Propietario. Al pincharlos el programa muestra un formulario de selección usuario recibe un formulario que le permite seleccionar un valor para el campo de entre los valores que están introducidos en el fichero correspondiente. Algo como esto:
En este formulario queda claro – o eso creo – que además de elegir el valor, se puede dar de alta, modificar o borrar un registro del fichero correspondiente.
mi solución
Mientras realizaba la última modificación de el Puchero surgió un problema adicional. El programa manejaba dos combos, uno de los cuales se tenía que cargar en función del valor de una serie de botones de selección. Lo difícil no era esto, era hacer el movimiento adelante – atrás por las recetas una vez que se entraba a editar una. Decidí dejar de usar comboboxes.
Había un problema añadido: usar bitmaps externos a los campos de edición trastocan mucho la estética del formulario. Es muy difícil conseguir una imagen de simetría correcta – ya explicaré esto un dia con detalle, lo prometo – con los dichosos bitmaps. La posible solución: usar la clase BtnGet de Ricardo Ramírez. No me convenció, pero su clase me aportó un trocito de código impagable.
Por aquellas fechas Patrick Mast puso en uno de los foros de Fivetech unos enlaces a pantallazos de su WinFakt donde mostraba lo que yo quería hacer y además explicaba como se hacia. Simplemente poniendo un bitmap al lado del get llevando cuidado de que se solapasen para que parecieran un sólo control. Una solución realmente elegante.
A partir de aquí fue todo muy sencillo y tuve resuelto mi problema: quitar los combos pero conservando la simetria de los dialogos, como muestro en la figura siguiente. El dialogo se despliega al hacer click en la imagen al lado del campo y queda claro que se pueden hacer altas, bajas y modificaciones de datos.
gracias a Ricardo
Al bajarme y probar la clase de BtnGet de Ricardo Ramirez encontré un trozo de código muy valioso, en que muestra como posicionar una ventana en la pantalla pegada a un control. Ahí va:
Uno de los controles que utilizo habitualmente en mis programas son los folders de Fivewin. Según el libro ‘ The Windows Interface Guidelines — A Guide for Designing Software’ este control se denomina TAB y presenta una analogía a los separadores de los cuadernos y permite mostrar varios páginas dentro de una ventana o dialogo, cada uno en una pestaña.
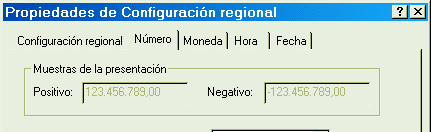
Los folders de Fivewin están pintados ‘a mano’, mediante la función FoldPaint() que se llama en el método Paint de la clase TFolder(). Esta función pinta los folders de la misma manera que Windows95 y ahí reside el problema: que los folders de Windows95 están mal diseñados desde el punto de vista de su usabilidad. Para verlo vamos a fijarnos en los folders de Windows95 y luego en sus competidores. Los de Windows95 son estos, de acuerdo a la imagen tomada de la configuración regional del panel de control:
Estos folders presentan los siguientes problemas:
Es difícil distinguir que pestaña está activa ya que no hay una diferenciación en tamaño y color entre la pestaña activa y las demás.
El problema de la diferenciación se agrava en cuanto cambiamos el esquema de colores de Windows y en especial el de la cara de botón por uno más claro que el definido por defecto. Los colores de la imagen corresponden a un sistema operativo Windows98 con los colores de XP y son los que uso habitualmente en uno de los sistemas operativos instalados en mi PC.
No utilizan aceleradores, por lo que es necesario usar el ratón para pasar de una pestaña a otra.
Veamos que aspecto tienen los folders de Gnome, Mac8 y Aqua – el último interfaz de Apple. Aquí los teneis entenéis en el citado orden:
Como se puede apreciar, el diseño de estos folders muestra de manera correcta cual es la pestaña activa mediante un realce de la misma o el oscurecimiento de las pestaña no activas. Los diseñadores de Microsoft han tomado nota de ello y en WindowsXP presentan unos folders que optan por un realce similar el modelo ‘Aqua’.
En los Folders de WindowsXP se ha reforzado la diferenciación visual entre la pestaña activa y las no activas, asi como la diferenciación del propio folder dentro de la ventana dándole un tono más claro que esta.
ahora con Fivewin
En mis aplicaciones utilizo dos tipos de folders:
Folders con imágenes
Folders sin imágenes
La idea en ambos casos es la misma: utilizar aceleradores en las pestañas y diferenciar entre la pestaña seleccionada y las que no están seleccionadas oscureciendo estas últimas. En los folders con imágenes cada pestaña lleva su bitmap, mientras que en los folders sin imágenes refuerzo del papel de la pestaña activa pintando una raya ‘a la XP’ sobre ella. El oscurecimiento de las pestañas no activas se hace sobre el tono del color de botón, normalmente con el color GetSysColor(15) – RGB40,40,40). Con ello me aseguro de que el oscurecimiento es sobre el color del botón, evitando poner un color arbitrario.
Estos folders son ligeras modificaciones de la clase C5Folders, por lo que no puedo publicar su código fuente. Sin embargo, creo que con las indicaciones dadas se podría hacer unos folders similares basados en la clase Folder de Fivewin.